
Wir haben eine unserer alten internen Rails-Anwendungen von Heroku, PostgreSQL und Heroku Scheduler auf unsere Kubernetes-Plattform, SQLite und etwas Bash-Magie migriert. Das Ergebnis ist überraschend gut!
Hintergrund
SQLite ist eine kleine, eingebettete, voll funktionsfähige Datenbank, die als einzelne Binärdatei auf der Festplatte gespeichert wird. Sie bietet eine schnelle, leichte, ACID-konforme Datenbank, ohne dass ein separater Dienst oder Netzwerkverbindungen erforderlich sind. Ursprünglich für eingebettete Geräte gedacht, hat sie sich im Laufe der Jahre zu einer sehr beliebten Alternative zu traditionellen Datenbanksystemen entwickelt.
Bei Harvest hatten wir einige interne Tools, die wir von Heroku auf unsere interne Kubernetes-Infrastruktur migrieren wollten. Eines davon verwendete eine Heroku PostgreSQL-Datenbankinstanz, und ich hatte Schwierigkeiten zu entscheiden, wie ich diese Anwendung am besten migrieren könnte.
Ursprünglich dachte ich daran, die Anwendung auf MySQL zu portieren, um mit unserer Produktionsdatenbank-Infrastruktur übereinzustimmen, aber ein Kollege schlug vor, dass wir uns SQLite als Alternative zu einem weiteren MySQL-Cluster ansehen sollten. Wenn das funktionierte, würde es sowohl die Bereitstellung der Anwendung vereinfachen als auch Geld sparen, indem wir viel weniger Pods betreiben.
Diese Anwendung ist ein internes Tool, das unserem Support-Team hilft, ihre Tickets im Blick zu behalten, und hatte zum Zeitpunkt der Migration nur etwa 30 MB Daten, sodass sie ein guter Kandidat für Experimente war.
Der Rewrite
Rails hat eingebaute Unterstützung für SQLite, also war es nur eine Frage, das SQLite-Gem herunterzuladen und die Datenbankkonfiguration einzurichten. Oder?
Nun, nicht ganz.
Obwohl SQL ein Standard ist, können verschiedene Datenbanken unterschiedliche Funktionen auf unterschiedliche Weise implementieren. Und die Abfragen dieser speziellen Anwendung basierten auf einigen PostgreSQL-spezifischen Datums- und Zeitfunktionen, die in SQLite nicht implementiert waren.
Ich musste die folgende ActiveRecord-Abfrage umwandeln.
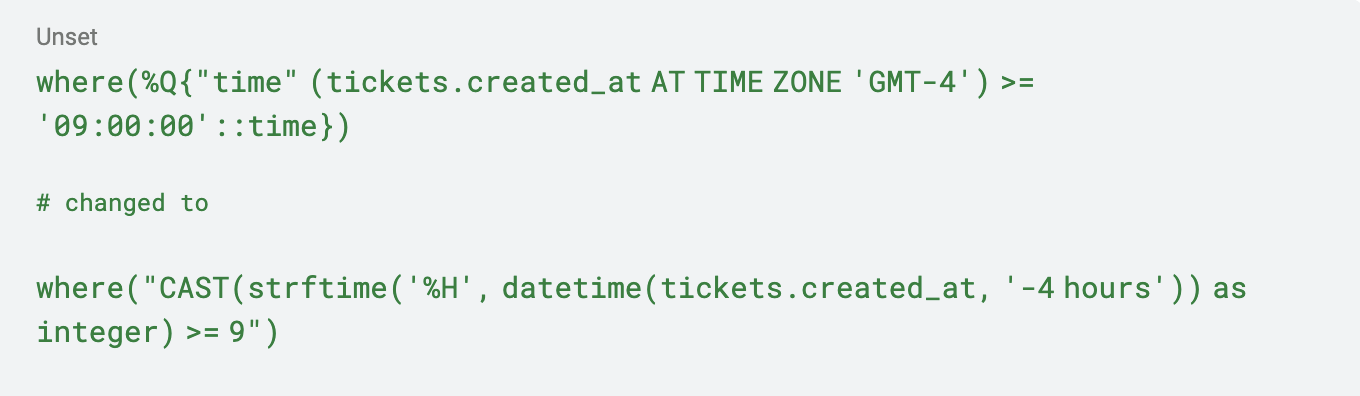
Obwohl dies eine schreckliche, fest codierte Datumsberechnung ist (die die Sommerzeit nicht berücksichtigt) und nicht die beste Lösung für das Problem darstellt, hat es funktioniert und mir ermöglicht, die Migration fortzusetzen. Insgesamt mussten etwa 20 Abfragen aktualisiert werden, aber glücklicherweise gab es Unit-Tests, die mir beim Refactoring halfen!
Bereitstellungsprobleme
Zu viele Pods
Sobald ich die Anwendung gut in meiner lokalen Entwicklungsumgebung zum Laufen gebracht hatte, machte ich mich daran, sie in einer Staging-Umgebung bereitzustellen. Hier wurde es interessant.
Da SQLite "Verbindungen" lediglich das Öffnen einer Datei im Dateisystem sind, muss die Datenbank selbst im Dateisystem des Containers sein. Das bedeutet, dass selbst wenn wir ein persistentes Volume einbinden, jeder Pod in einer Bereitstellung eine andere Version der Daten sieht. Normalerweise wäre das ein Ausschlusskriterium — aber für diese Anwendung hat es am Ende gut funktioniert.
Ich habe einfach ein einzelnes Replica StatefulSet erstellt, das die Daten eingebunden hat, sodass die Anwendung nach einem Pod-Neustart weiterhin auf alle ihre Daten zugreifen kann. Hier ist eine vereinfachte Version dessen, was ich am Ende hatte.

Aber warte, es gibt noch mehr!
CronJobs? Warum muss es immer CronJobs sein?
Diese Anwendung hatte auch einige regelmäßige Datenaktualisierungsaufgaben, die ausgeführt werden mussten. Zuvor wurden diese mit einem Heroku Scheduler implementiert, also versuchte ich, sie mit einem Kubernetes CronJob nachzubauen, aber diese erstellen bei jedem Lauf einen neuen Pod. Normalerweise wäre das ideal, aber wir stoßen auf das Problem, dass jeder Pod seine eigenen Daten erhält. Der Job würde erfolgreich ausgeführt, und dann wären die Daten verloren, wenn der Pod beendet wird. Das würde nicht funktionieren, also musste ich eine neue, innovative Lösung finden.
Alle Aktualisierungen müssen innerhalb desselben Pods erfolgen, also habe ich 2 separate Sidecar-Container erstellt, die mit folgendem Befehl starten:

Dieser Befehl führt alle 10 Minuten die Rails-Aufgabe aus und schläft den Rest der Zeit.
Es funktioniert, weil alle Container im StatefulSet-Pod mit denselben Volume-Mounts laufen. Es ist im Grunde nur ein zusätzlicher Prozess, der Zugriff auf dieselben Dateien hat und das inkrementelle Update wie erwartet durchführt.
Sobald dies bereit war, um in die Produktion zu gehen, benötigte ich eine Möglichkeit, das Datenbankschema zu initialisieren und einen vollständigen Datenimport zu starten. Glücklicherweise gab es eine Rails-Migration, die ich ausführen konnte. Alles, was ich tun musste, war, in den Pod des StatefulSets zu execen und den Befehl rails database:migrate auszuführen.
Nachteile dieses Ansatzes
Obwohl dies für uns in diesem speziellen Anwendungsfall funktionierte, gibt es einige Nachteile dieses Ansatzes.
Der größte Nachteil ist, dass Sie das StatefulSet nicht über einen einzelnen Pod hinaus skalieren können. Das wäre schrecklich, wenn diese Anwendung öffentlichen Verkehr erwarten würde, aber es handelt sich um ein einfaches internes Automatisierungstool für Geschäftsprozesse, das einfach laufen muss, also funktioniert es perfekt. Nur ein Pod bedeutet, dass wir manchmal Ausfallzeiten während der Upgrades des Kubernetes-Knotenpools haben.
Ein weiterer Nachteil ist der Mangel an Werkzeugen. Um sich mit der Datenbank zu "verbinden", müssen Sie in den laufenden Pod shellen und sqlite3-Befehle lokal ausführen, um Wartungsarbeiten an der Datenbank durchzuführen, falls erforderlich. Obwohl das ziemlich gut funktioniert, ist es im Vergleich zur Verbindung mit einer Remote-Datenbank etwas umständlich.
Der Mangel an Unterstützung durch andere Bibliotheken ist ebenfalls ein Problem. Während SQLite von vielen Programmiersprachen gut unterstützt wird, erhält es oft weniger Unterstützung in Bezug auf ORM-Bibliotheken. Für uns unterstützte Rails ActiveRecord alles, was wir benötigten, aber das Unterstützungsniveau ist anders als bei MySQL.
Insgesamt überraschend gut!
Durch diese Migration konnten wir unsere Heroku-Kosten um etwa 90 USD pro Monat senken und sie durch einen einzelnen Pod ersetzen, der in unseren bestehenden Kubernetes-Clustern läuft. Wenn Sie zufällig fünf oder sechs ähnliche interne Tools in Ihrer Umgebung haben, könnte dies eine großartige Option sein, um Ihre Bereitstellung zu vereinfachen.
Was die Leistung betrifft, so verringerte sich die Ladezeit der Anwendung um etwa 150 ms. Obwohl wir nicht auf Geschwindigkeit optimiert haben, verbessert es die Nutzung erheblich.
Es läuft jetzt seit mehreren Monaten intern in der Produktion und ist äußerst stabil.
In Zukunft fände ich es interessant zu sehen, wie diese Anwendung mit etwas wie https://dqlite.io/ aussieht, um die Daten automatisch über ein Raft-Cluster zu replizieren. Aber das wird wahrscheinlich einen eigenen Artikel erfordern.
Vollständige Lösung StatefulSet yaml

1. Die Neugestaltung der Anwendung war nicht genau im Umfang, und ich wollte trotzdem sehen, ob die Idee funktionierte
2. Auch bekannt als eine hacky Lösung.



