
Movimos una de nuestras aplicaciones internas heredadas de Rails de Heroku, PostgreSQL y Heroku Scheduler a nuestra plataforma Kubernetes, SQLite y un poco de magia en Bash. ¡El resultado final es sorprendentemente bueno!
Antecedentes
SQLite es una base de datos pequeña, embebida y completamente funcional que se persiste en disco como un solo archivo binario. Ofrece una base de datos rápida, ligera y compatible con ACID sin necesidad de ejecutar un servicio separado o usar conexiones de red. Aunque su uso previsto era para dispositivos embebidos, ha crecido a lo largo de los años como una alternativa muy popular a los sistemas de bases de datos tradicionales.
En Harvest, teníamos algunas herramientas internas que estábamos migrando de Heroku a nuestra infraestructura interna de Kubernetes. Una de ellas utilizaba una instancia de base de datos PostgreSQL de Heroku, y estaba luchando por decidir la mejor manera de migrar esta aplicación.
Originalmente, pensé en portar la aplicación a MySQL para que coincidiera con nuestra infraestructura de base de datos de producción, pero un compañero sugirió que deberíamos considerar SQLite como una alternativa a ejecutar otro clúster de MySQL. Suponiendo que esto funcionara, simplificaría el despliegue de la aplicación y nos ahorraría dinero al ejecutar muchos menos pods.
Esta aplicación es una herramienta solo interna que ayuda a nuestro equipo de soporte a llevar un seguimiento de sus tickets y solo tenía alrededor de 30MB de datos en el momento de la migración, así que parecía un buen candidato para experimentar.
La reescritura
Rails tiene soporte integrado para SQLite, así que solo era cuestión de bajar la gema de SQLite y configurar la base de datos. ¿Verdad?
Bueno, no exactamente.
Aunque SQL es un estándar, diferentes bases de datos pueden elegir implementar diferentes características de distintas maneras. Y las consultas de esta aplicación en particular dependían de algunas funcionalidades específicas de fecha y hora de PostgreSQL que no estaban implementadas en SQLite.
Tuve que tomar la siguiente consulta de ActiveRecord y convertirla.
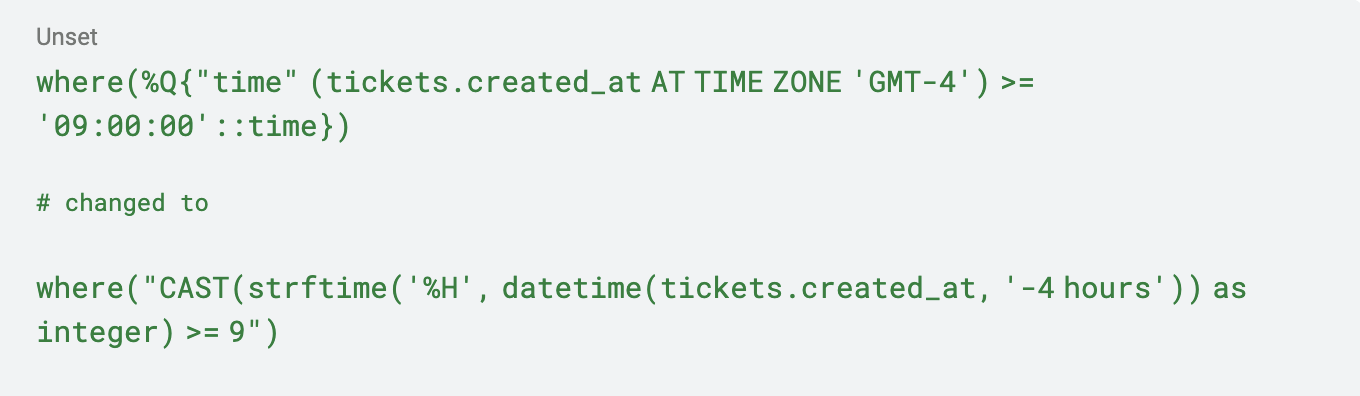
Aunque esto es una terrible matemática de fecha codificada (que no toma en cuenta el horario de verano), y no es la mejor manera de solucionar el problema, funcionó y me permitió seguir migrando. En total, alrededor de 20 consultas necesitaban ser actualizadas, pero afortunadamente había pruebas unitarias para ayudarme a refactorizar.
Complicaciones en el despliegue
Demasiados pods
Una vez que logré que la aplicación funcionara bien en mi entorno de desarrollo local, me propuse desplegarla en un entorno de staging. Aquí es donde se puso interesante.
Dado que las “conexiones” de SQLite son simplemente abrir un archivo en el sistema de archivos, la base de datos misma necesita estar en el sistema de archivos del contenedor. Esto significa que incluso si montamos un volumen persistente, cada pod en un despliegue verá una versión diferente de los datos. Normalmente, esto sería un obstáculo, pero para esta aplicación funcionó bien al final.
Terminé creando un StatefulSet de réplica única que tiene los datos montados para que la aplicación mantuviera acceso a todos sus datos al reiniciar el pod. Aquí hay una versión simplificada de lo que terminé.

¡Pero espera, hay más!
¿CronJobs? ¿Por qué siempre tiene que ser CronJobs?
Esta aplicación también tenía algunas tareas de actualización de datos periódicas que necesitaban ser ejecutadas. Anteriormente, estas se implementaban con un Heroku Scheduler, así que intenté recrearlas con un Kubernetes CronJob, pero esos crean un nuevo pod con cada ejecución. Normalmente, esto sería ideal, pero nos encontramos con el problema de que cada pod obtiene sus propios datos. El trabajo se ejecutaría con éxito y luego los datos se perderían cuando el pod terminara. Eso no funcionaría, así que tuve que idear una nueva solución innovadora.
Cualquier actualización debe ocurrir dentro del mismo pod, así que creé 2 contenedores sidecar separados que inician con el siguiente comando:

Este comando ejecutará la tarea de Rails cada 10 minutos, durmiendo el resto del tiempo.
Funciona porque todos los contenedores en el pod de StatefulSet se ejecutan con los mismos montajes de volumen. Es esencialmente solo un proceso adicional que tiene acceso a los mismos archivos y realiza la actualización incremental como se esperaba.
Una vez que esto estuvo listo para entrar en producción, necesitaba una forma de sembrar el esquema de la base de datos y comenzar una carga completa de datos. Afortunadamente, había una migración de Rails que podía ejecutar. Todo lo que tenía que hacer era acceder al pod del StatefulSet y ejecutar el comando rails database:migrate.
Desventajas de este enfoque
Si bien esto funcionó para nosotros en este caso específico, hay algunas desventajas en este enfoque.
La más grande es que no puedes escalar el StatefulSet más allá de un solo pod. Esto sería terrible si esta aplicación esperara aceptar tráfico público, pero es una simple herramienta de automatización de procesos internos que solo necesita funcionar, así que funciona perfectamente. Tener solo un pod significa que a veces incurrimos en tiempo de inactividad durante las actualizaciones del grupo de nodos de Kubernetes.
Otra desventaja es la falta de herramientas. Para “conectarte” a la base de datos, necesitas acceder al pod en ejecución y ejecutar comandos sqlite3 localmente para hacer cualquier mantenimiento de la base de datos si es necesario. Si bien esto funciona bastante bien, es un poco incómodo en comparación con conectarse a una base de datos remota.
La falta de soporte de otras bibliotecas también es un problema. Si bien SQLite está bien soportado por muchos lenguajes de programación, a menudo recibe menos soporte en términos de bibliotecas ORM. Para nosotros, Rails ActiveRecord soportó todo lo que necesitábamos, pero el nivel de soporte es diferente al de MySQL.
En general, sorprendentemente no está mal!
Al hacer esta migración, pudimos reducir nuestro costo en Heroku en alrededor de $90/mes USD y reemplazarlo con un solo pod ejecutándose en nuestros clústeres de Kubernetes existentes. Si tienes cinco o seis herramientas internas similares flotando en tu entorno, esta podría ser una gran opción para simplificar tu despliegue.
En cuanto al rendimiento, el tiempo de carga de la página de la aplicación disminuyó en aproximadamente 150ms. Si bien no estábamos optimizando para velocidad, mejora mucho la experiencia de uso.
Ha estado funcionando en producción internamente durante varios meses y ha sido muy estable.
Mirando hacia el futuro, creo que sería interesante ver cómo se vería esta aplicación con algo como https://dqlite.io/ para replicar automáticamente los datos a través de un clúster de Raft. Pero eso probablemente requerirá su propio artículo.
YAML completo de solución StatefulSet

1. Rehacer la aplicación no estaba exactamente en el alcance, y aún quería ver si la idea funcionaba
2. También conocido como una solución improvisada.



