
Nous avons migré l'une de nos anciennes applications internes Rails de Heroku, PostgreSQL et Heroku Scheduler vers notre plateforme Kubernetes, SQLite et un peu de magie Bash. Le résultat final est étonnamment pas mal !
Contexte
SQLite est une petite base de données intégrée, complète, qui est persistée sur disque sous forme d'un seul fichier binaire. Elle offre une base de données rapide, légère et conforme à l'ACID sans avoir besoin d'exécuter un service séparé ou d'utiliser des connexions réseau. Bien que son utilisation initiale était pour des appareils intégrés, elle est devenue au fil des ans une alternative très populaire aux systèmes de bases de données traditionnels.
Chez Harvest, nous avions quelques outils internes que nous migrions de Heroku vers notre infrastructure Kubernetes interne. L'un d'eux utilisait une instance de base de données PostgreSQL sur Heroku, et j'avais du mal à décider comment migrer cette application.
Au départ, j'ai pensé à porter l'application sur MySQL pour correspondre à notre infrastructure de base de données de production, mais un collègue a suggéré que nous devrions envisager SQLite comme alternative à un autre cluster MySQL. Si cela fonctionnait, cela simplifierait le déploiement de l'application et nous ferait économiser de l'argent en exécutant beaucoup moins de pods.
Cette application est un outil interne qui aide notre équipe de support à suivre ses tickets et elle ne contenait qu'environ 30 Mo de données au moment de la migration, donc cela semblait être un bon candidat pour expérimenter.
La réécriture
Rails prend en charge SQLite, donc il suffisait de télécharger la gem SQLite et de configurer la base de données. Non ?
Eh bien, pas exactement.
Bien que SQL soit un standard, différentes bases de données peuvent choisir d'implémenter différentes fonctionnalités de différentes manières. Et les requêtes de cette application particulière dépendaient de certaines fonctionnalités de date-heure spécifiques à PostgreSQL qui n'étaient pas implémentées dans SQLite.
J'ai dû prendre la requête ActiveRecord suivante et la convertir.
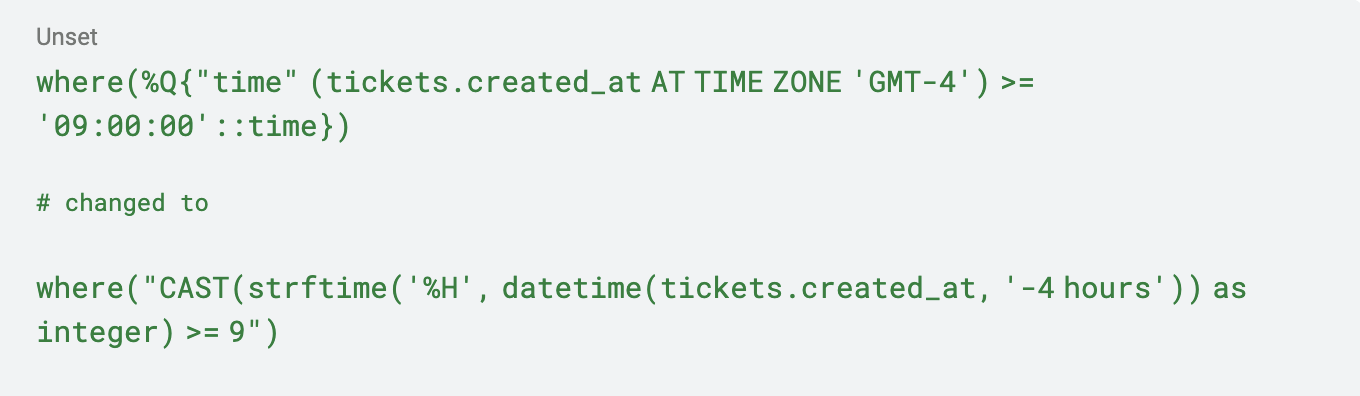
Bien que ce soit une terrible mathématique de date codée en dur (qui ne prend pas en compte l'heure d'été), et n'est pas la meilleure façon de résoudre le problème, cela a fonctionné et m'a permis de continuer la migration. Au total, environ 20 requêtes ont dû être mises à jour, mais heureusement, il y avait des tests unitaires pour m'aider à refactoriser !
Complications de déploiement
Trop de pods
Une fois que j'ai réussi à faire fonctionner l'application sur mon environnement de développement local, je me suis lancé dans le déploiement vers un environnement de staging. C'est là que cela est devenu intéressant.
Comme les "connexions" SQLite consistent simplement à ouvrir un fichier sur le système de fichiers, la base de données elle-même doit être sur le système de fichiers du conteneur. Cela signifie que même si nous montons un volume persistant, chaque pod dans un déploiement verra une version différente des données. Normalement, cela serait un obstacle — mais pour cette application, cela a bien fonctionné au final.
J'ai fini par créer un StatefulSet à réplique unique StatefulSet qui a les données montées afin que l'application conserve l'accès à toutes ses données lors du redémarrage du pod. Voici une version simplifiée de ce que j'ai obtenu.

Mais attendez, ce n'est pas tout !
CronJobs ? Pourquoi ça doit toujours être des CronJobs ?
Cette application avait également des tâches de rafraîchissement de données périodiques qui devaient être exécutées. Auparavant, celles-ci étaient mises en œuvre avec un Heroku Scheduler, donc j'ai tenté de les recréer avec un Kubernetes CronJob, mais ceux-ci créent un nouveau pod à chaque exécution. Normalement, cela serait idéal, mais nous rencontrons le problème où chaque pod obtient ses propres données. Le travail s'exécuterait avec succès, puis les données seraient perdues lorsque le pod se terminait. Cela ne fonctionnerait pas, donc j'ai dû trouver une nouvelle solution innovante.
Toutes les mises à jour doivent se faire dans le même pod, donc j'ai créé 2 conteneurs sidecar séparés qui démarrent avec la commande suivante :

Cette commande exécutera la tâche rails toutes les 10 minutes, dormant le reste du temps.
Ça fonctionne parce que tous les conteneurs dans le pod StatefulSet s'exécutent avec les mêmes montages de volume. C'est essentiellement juste un processus supplémentaire qui a accès aux mêmes fichiers et effectue la mise à jour incrémentielle comme prévu.
Une fois que cela était prêt à être mis en production, j'avais besoin d'un moyen de peupler le schéma de la base de données et de lancer un chargement complet des données. Heureusement, il y avait une migration rails que je pouvais exécuter. Tout ce que j'avais à faire était d'exécuter le pod du StatefulSet et de lancer la commande rails database:migrate.
Inconvénients de cette approche
Bien que cela ait fonctionné pour nous dans ce cas d'utilisation spécifique, il y a quelques inconvénients à cette approche.
Le plus gros est que vous ne pouvez pas faire évoluer le StatefulSet au-delà d'un seul pod. Cela serait terrible si cette application s'attendait à accepter du trafic public, mais c'est un simple outil d'automatisation des processus internes qui doit juste fonctionner, donc cela fonctionne parfaitement. Avoir un seul pod signifie que nous subissons parfois des temps d'arrêt lors des mises à jour du pool de nœuds Kubernetes.
Un autre inconvénient est le manque d'outils. Pour "se connecter" à la base de données, vous devez accéder au pod en cours d'exécution et exécuter des commandes sqlite3 localement pour effectuer toute maintenance de la base de données si nécessaire. Bien que cela fonctionne assez bien, c'est un peu gênant par rapport à la connexion à une base de données distante.
Le manque de support d'autres bibliothèques est également un problème. Bien que SQLite soit bien pris en charge par de nombreux langages de programmation, il reçoit souvent moins de soutien en termes de bibliothèques ORM. Pour nous, Rails ActiveRecord a pris en charge tout ce dont nous avions besoin, mais le niveau de support est différent de celui de MySQL.
Dans l'ensemble, étonnamment pas mal !
En effectuant cette migration, nous avons pu réduire nos coûts Heroku d'environ 90 $/mois USD et les remplacer par un seul pod fonctionnant dans nos clusters Kubernetes existants. Si vous avez cinq ou six outils internes similaires dans votre environnement, cela pourrait être une excellente option pour simplifier votre déploiement.
En ce qui concerne les performances, le temps de chargement de la page de l'application a diminué d'environ 150 ms. Bien que nous ne cherchions pas à optimiser la vitesse, cela améliore considérablement l'expérience d'utilisation.
Elle fonctionne en production en interne depuis plusieurs mois maintenant et est très stable.
En regardant vers l'avenir, je pense qu'il serait intéressant de voir à quoi ressemble cette application avec quelque chose comme https://dqlite.io/ pour répliquer automatiquement les données à travers un cluster Raft. Mais cela nécessitera probablement son propre article.
Solution complète StatefulSet yaml

1. Revoir l'application n'était pas exactement dans le périmètre, et je voulais quand même voir si l'idée fonctionnait
2. Également connu comme une solution de contournement astucieuse.



