
Abbiamo migrato una delle nostre applicazioni Rails legacy da Heroku, PostgreSQL e Heroku Scheduler alla nostra piattaforma Kubernetes, SQLite e un po' di magia Bash. Il risultato finale è sorprendentemente non male!
Contesto
SQLite è un database piccolo, integrato e completo, memorizzato su disco come un singolo file binario. Offre un database veloce e leggero, conforme ad ACID, senza la necessità di eseguire un servizio separato o utilizzare connessioni di rete. Sebbene il suo uso previsto fosse per dispositivi embedded, nel tempo è diventato un'alternativa molto popolare ai sistemi di database tradizionali.
In Harvest, avevamo alcuni strumenti interni che stavamo migrando da Heroku alla nostra infrastruttura Kubernetes. Uno di questi utilizzava un'istanza di database PostgreSQL su Heroku, e stavo cercando di capire come migrare al meglio questa applicazione.
Inizialmente, pensavo di portare l'applicazione su MySQL per allinearla alla nostra infrastruttura di database di produzione, ma un collega ha suggerito di considerare SQLite come alternativa per non dover gestire un altro cluster MySQL. Se avesse funzionato, avrebbe semplificato il deployment dell'applicazione e ci avrebbe fatto risparmiare denaro eseguendo molti meno pod.
Questa applicazione è uno strumento interno che aiuta il nostro team di supporto a tenere traccia dei ticket e aveva solo circa 30MB di dati al momento della migrazione, quindi sembrava un buon candidato per sperimentare.
La riscrittura
Rails ha supporto integrato per SQLite, quindi era solo una questione di scaricare la gemma SQLite e configurare il database. Giusto?
Bene, non esattamente.
Sebbene SQL sia uno standard, i diversi database possono scegliere di implementare funzionalità diverse in modi diversi. E le query di questa particolare applicazione si basavano su alcune funzionalità specifiche di PostgreSQL per la gestione delle date che non erano implementate in SQLite.
Ho dovuto prendere la seguente query ActiveRecord e convertirla.
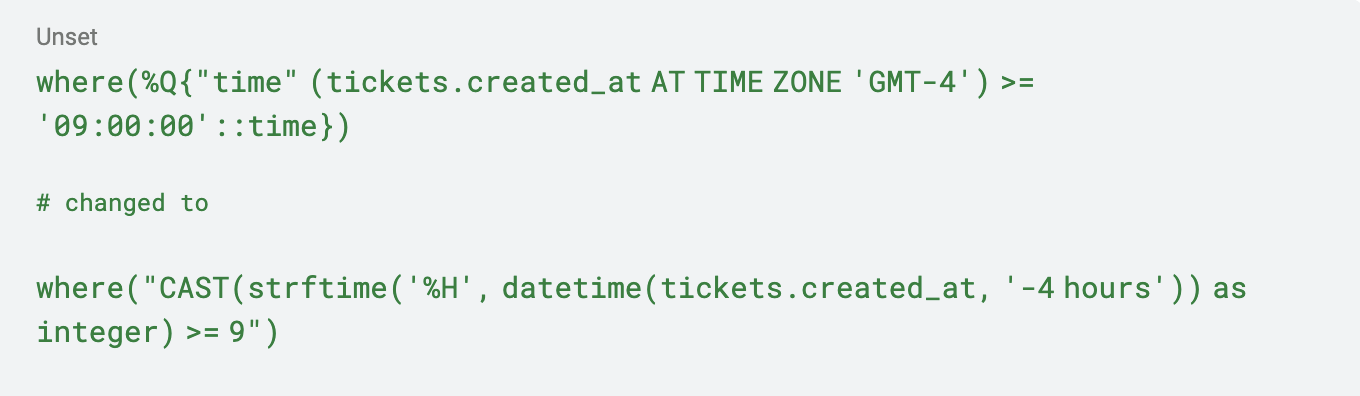
Sebbene questa sia una terribile matematica delle date hard-coded (che non tiene conto dell'ora legale), e non sia il modo migliore per risolvere il problema, ha funzionato e mi ha permesso di continuare a migrare. In totale, circa 20 query dovevano essere aggiornate, ma fortunatamente c'erano test unitari per aiutarmi a rifattorizzare!
Complicazioni nel deployment
Troppi pod
Una volta che l'applicazione ha iniziato a funzionare bene nel mio ambiente di sviluppo locale, ho cercato di distribuirla in un ambiente di staging. Qui è diventato interessante.
Poiché le "connessioni" di SQLite sono semplicemente l'apertura di un file nel filesystem, il database stesso deve trovarsi nel filesystem del container. Questo significa che anche se montiamo un volume persistente, ogni pod in un deployment vedrà una versione diversa dei dati. Normalmente, questo sarebbe un problema — ma per questa applicazione alla fine ha funzionato bene.
Ho finito per creare un single-replica StatefulSet che ha i dati montati in modo che l'applicazione mantenesse accesso a tutti i suoi dati al riavvio del pod. Ecco una versione semplificata di ciò che ho ottenuto.

Ma aspetta, c'è di più!
CronJobs? Perché deve sempre essere CronJobs?
Questa applicazione aveva anche alcune attività di aggiornamento dati periodiche che dovevano essere eseguite. In precedenza, queste erano implementate con un Heroku Scheduler, quindi ho tentato di ricrearle con un Kubernetes CronJob, ma questi creano un nuovo pod ad ogni esecuzione. Normalmente, questo sarebbe ideale, ma ci troviamo di fronte al problema in cui ogni pod ottiene i propri dati. Il lavoro si sarebbe eseguito con successo, e poi i dati sarebbero andati persi quando il pod terminava. Questo non avrebbe funzionato, quindi ho dovuto trovare una nuova soluzione innovativa.
Tutti gli aggiornamenti devono avvenire all'interno dello stesso pod, quindi ho creato 2 container sidecar separati che partono con il seguente comando:

Questo comando eseguirà il task di Rails ogni 10 minuti, dormendo il resto del tempo.
Funziona perché tutti i container nel pod StatefulSet eseguono gli stessi mount di volume. È essenzialmente solo un processo extra che ha accesso agli stessi file e esegue l'aggiornamento incrementale come previsto.
Una volta che questo era pronto per la produzione, avevo bisogno di un modo per inizializzare lo schema del database e avviare un caricamento completo dei dati. Fortunatamente, c'era una migrazione di Rails che potevo eseguire. Tutto ciò che dovevo fare era entrare nel pod dello StatefulSet ed eseguire il comando rails database:migrate.
Svantaggi di questo approccio
Sebbene questo abbia funzionato per noi in questo caso specifico, ci sono alcuni svantaggi in questo approccio.
Il più grande è che non puoi scalare lo StatefulSet oltre un singolo pod. Questo sarebbe terribile se questa applicazione si aspettasse di ricevere traffico pubblico, ma essendo uno strumento di automazione dei processi aziendali interno e semplice, funziona perfettamente. Avere solo un pod significa che a volte subiamo downtime durante gli aggiornamenti del pool di nodi Kubernetes.
Un altro svantaggio è la mancanza di strumenti. Per "connettersi" al database, devi entrare nel pod in esecuzione ed eseguire comandi sqlite3 localmente per fare eventuali manutenzioni del database se necessario. Sebbene questo funzioni abbastanza bene, è un po' scomodo rispetto alla connessione a un database remoto.
La mancanza di supporto da parte di altre librerie è anche un problema. Sebbene SQLite sia ben supportato da molti linguaggi di programmazione, spesso riceve meno supporto in termini di librerie ORM. Per noi, Rails ActiveRecord supportava tutto ciò di cui avevamo bisogno, ma il livello di supporto è diverso rispetto a MySQL.
Nel complesso, sorprendentemente non male!
Facendo questa migrazione, siamo riusciti a ridurre i nostri costi su Heroku di circa $90/mese USD e sostituirlo con un singolo pod in esecuzione nei nostri cluster Kubernetes esistenti. Se hai cinque o sei strumenti simili solo interni nel tuo ambiente, questa potrebbe essere una grande opzione per semplificare il tuo deployment.
Per quanto riguarda le prestazioni, il tempo di caricamento della pagina dell'applicazione è diminuito di circa 150ms. Anche se non stavamo ottimizzando per la velocità, questo migliora notevolmente l'esperienza d'uso.
È in produzione internamente da diversi mesi e si è dimostrata molto stabile.
Guardando al futuro, penso che sarebbe interessante vedere come appare questa applicazione con qualcosa come https://dqlite.io/ per replicare automaticamente i dati attraverso un cluster raft. Ma probabilmente richiederà un articolo a parte.
Soluzione completa StatefulSet yaml

1. Rielaborare l'applicazione non era esattamente in programma, e volevo comunque vedere se l'idea funzionava
2. Conosciuto anche come una soluzione improvvisata.



