
私たちは、Heroku、PostgreSQL、Heroku SchedulerからKubernetesプラットフォーム、SQLite、そしていくつかのBashの魔法に移行しました。最終的な結果は意外と悪くありませんでした!
背景
SQLiteは、小型で埋め込み可能な完全機能のデータベースで、単一のバイナリファイルとしてディスクに保存されます。別のサービスを実行したり、ネットワーク接続を使用することなく、迅速で軽量なACID準拠のデータベースを提供します。元々は埋め込みデバイス向けに設計されましたが、年々、従来のデータベースシステムの人気のある代替手段となりました。
Harvestでは、Herokuから内部のKubernetesインフラに移行するいくつかの内部ツールがありました。そのうちの1つはHeroku PostgreSQLデータベースインスタンスを使用しており、どのようにこのアプリケーションを移行するか決めかねていました。
最初は、プロダクションデータベースインフラに合わせてMySQLに移植することを考えましたが、同僚がSQLiteを別のMySQLクラスターの代替として検討することを提案しました。これがうまくいけば、アプリケーションのデプロイが簡素化され、ポッドの数を大幅に減らすことでコストも削減できるはずです。
このアプリケーションは内部専用のツールで、サポートチームがチケットを管理するのを助けるもので、移行時には約30MBのデータしかなかったため、実験するには良い候補でした。
書き換え
RailsはSQLiteを内蔵サポートしているため、SQLiteのgemをダウンロードし、データベース設定を行うだけのはずでした。
しかし、実際にはそう簡単ではありませんでした。
SQLは標準ですが、異なるデータベースは異なる方法で異なる機能を実装することができます。この特定のアプリケーションのクエリは、SQLiteには実装されていないPostgreSQL特有の日時機能に依存していました。
以下のActiveRecordクエリを変換する必要がありました。
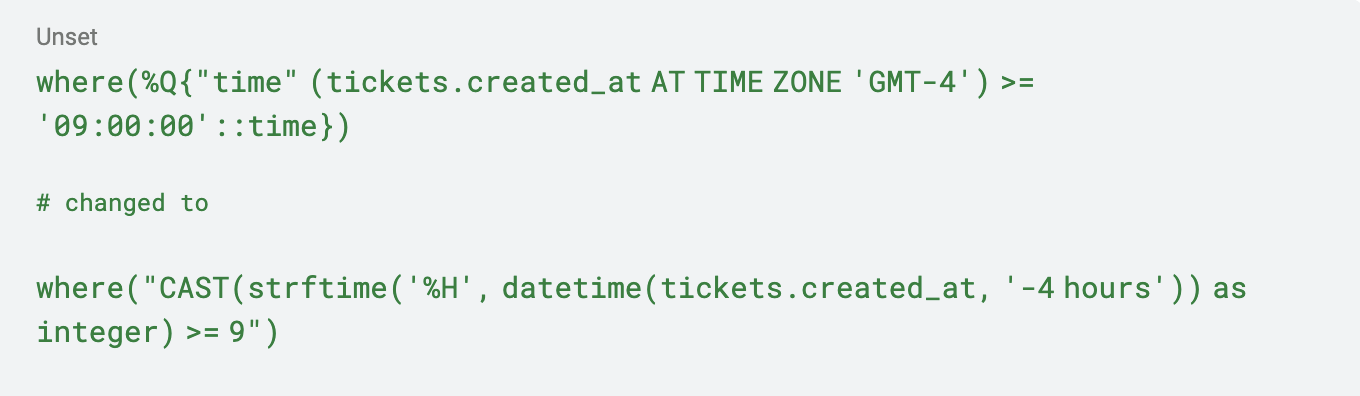
これはひどいハードコーディングされた日付計算(夏時間を考慮していない)ですが、問題を解決する最良の方法ではありませんが、機能し、移行を続けることができました。全体で約20のクエリを更新する必要がありましたが、幸いにもリファクタリングを助けるユニットテストがありました!
デプロイの複雑さ
ポッドが多すぎる
アプリケーションがローカル開発環境でうまく動作するようになったら、ステージング環境にデプロイすることにしました。ここからが面白くなります。
SQLiteの「接続」はファイルシステム上のファイルを開くだけなので、データベース自体はコンテナのファイルシステム上に存在する必要があります。これは、永続ボリュームをマウントしても、デプロイメント内の各ポッドが異なるデータのバージョンを表示することを意味します。通常、これは致命的な問題ですが、このアプリケーションでは最終的にうまくいきました。
私は、データがポッド再起動時にすべてのデータにアクセスできるように、データをマウントした単一レプリカStatefulSetを作成しました。最終的に得られたものの簡略版は以下の通りです。

でも、まだ続きがあります!
CronJobs?なぜいつもCronJobsなのか?
このアプリケーションには、定期的にデータを更新するタスクもありました。以前は、Heroku Schedulerを使用して実装されていたため、Kubernetes CronJobで再現しようとしましたが、それらは実行ごとに新しいポッドを作成します。通常、これは理想的ですが、各ポッドが独自のデータを持つという問題が発生しました。ジョブは正常に実行され、その後ポッドが終了するとデータが失われてしまいます。これは機能しないので、新しい革新的な解決策を考え出す必要がありました。
すべての更新は同じポッド内で行う必要があるため、次のコマンドで起動する2つのサイドカーコンテナを作成しました:

このコマンドは、10分ごとにRailsタスクを実行し、残りの時間はスリープします。
これは、StatefulSetポッド内のすべてのコンテナが同じボリュームマウントで実行されるため機能します。基本的には、同じファイルにアクセスできる追加のプロセスを生成し、期待通りにインクリメンタルな更新を行います。
これが本番環境に入る準備が整ったとき、データベーススキーマをシードし、完全なデータロードを開始する方法が必要でした。幸いにも、実行できるRailsマイグレーションがありました。私がやるべきことは、StatefulSetのポッドにexecして、rails database:migrateコマンドを実行することだけでした。
このアプローチの欠点
この特定のユースケースではうまくいきましたが、このアプローチにはいくつかの欠点があります。
最大の欠点は、StatefulSetを単一のポッド以上にスケールできないことです。このアプリケーションが公開トラフィックを受け入れることを期待している場合、これはひどいことですが、これは単純な内部ビジネスプロセス自動化ツールであり、ただ動作する必要があるため、完璧に機能します。ポッドが1つだけであるため、Kubernetesノードプールのアップグレード中にダウンタイムが発生することがあります。
もう1つの欠点は、ツールが不足していることです。データベースに「接続」するには、実行中のポッドにシェルで入って、必要に応じてローカルでsqlite3コマンドを実行する必要があります。これは比較的うまく機能しますが、リモートデータベースに接続するのに比べて少し不便です。
他のライブラリからのサポートが不足していることも問題です。SQLiteは多くのプログラミング言語でよくサポートされていますが、ORMライブラリに関してはサポートが少ないことがよくあります。私たちにとって、Rails ActiveRecordは必要なすべてをサポートしていましたが、サポートのレベルはMySQLとは異なります。
全体的に、意外と悪くない!
この移行により、Herokuのコストを月約90ドル削減し、既存のKubernetesクラスターで動作する単一のポッドに置き換えることができました。もし、あなたの環境に5つか6つの同様の内部専用ツールがあるなら、デプロイを簡素化するための素晴らしい選択肢になるかもしれません。
パフォーマンスについては、アプリケーションのページロード時間が約150ms短縮されました。速度を最適化していたわけではありませんが、使用体験が大幅に向上しました。
内部で数ヶ月間本番環境で稼働しており、非常に安定しています。
今後は、https://dqlite.io/のようなもので、このアプリケーションがラフトクラスター全体でデータを自動的に複製する様子を見てみるのも面白いと思います。しかし、それには別の記事が必要になるでしょう。
完全なソリューションのStatefulSet yaml

1. アプリケーションの再構築は正確には範囲外でしたが、アイデアが機能するかどうかを確認したかった
2. ハッキーなワークアラウンドとも呼ばれます。



