
우리는 Heroku, PostgreSQL, Heroku Scheduler에서 Kubernetes 플랫폼, SQLite 및 Bash 마법으로 우리의 레거시 내부 Rails 애플리케이션 중 하나를 이전했습니다. 최종 결과는 의외로 괜찮았습니다!
배경
SQLite는 단일 바이너리 파일로 디스크에 지속되는 작고 내장된 완전한 기능의 데이터베이스입니다. 별도의 서비스를 실행하거나 네트워크 연결을 사용할 필요 없이 빠르고 가벼운 ACID 호환 데이터베이스를 제공합니다. 원래는 내장 장치용으로 설계되었지만, 시간이 지나면서 전통적인 데이터베이스 시스템에 대한 매우 인기 있는 대안으로 성장했습니다.
Harvest에서는 Heroku에서 내부 Kubernetes 인프라로 이전하고 있는 몇 가지 내부 도구가 있었습니다. 그 중 하나는 Heroku PostgreSQL 데이터베이스 인스턴스를 사용하고 있었고, 이 애플리케이션을 어떻게 이전할지 결정하는 데 어려움을 겪고 있었습니다.
처음에는 애플리케이션을 MySQL로 포팅하여 우리의 프로덕션 데이터베이스 인프라와 일치시키는 것을 고려했지만, 동료가 MySQL 클러스터를 추가로 실행하는 대신 SQLite를 대안으로 고려해보자고 제안했습니다. 이것이 작동한다면 애플리케이션 배포를 단순화하고 훨씬 적은 수의 파드를 실행하여 비용을 절감할 수 있었습니다.
이 애플리케이션은 지원 팀이 티켓을 추적하는 데 도움을 주는 내부 전용 도구로, 이전 당시 약 30MB의 데이터만 있었기 때문에 실험하기에 좋은 후보처럼 보였습니다.
재작성
Rails는 SQLite에 대한 기본 지원을 제공하므로 SQLite gem을 다운로드하고 데이터베이스 구성을 설정하는 것만으로 충분했습니다. 맞죠?
글쎄요, 정확히는 그렇지 않았습니다.
SQL은 표준이지만, 서로 다른 데이터베이스는 서로 다른 방식으로 서로 다른 기능을 구현할 수 있습니다. 그리고 이 특정 애플리케이션의 쿼리는 SQLite에서 구현되지 않은 PostgreSQL 특정 날짜-시간 기능에 의존하고 있었습니다.
저는 다음 ActiveRecord 쿼리를 변환해야 했습니다.
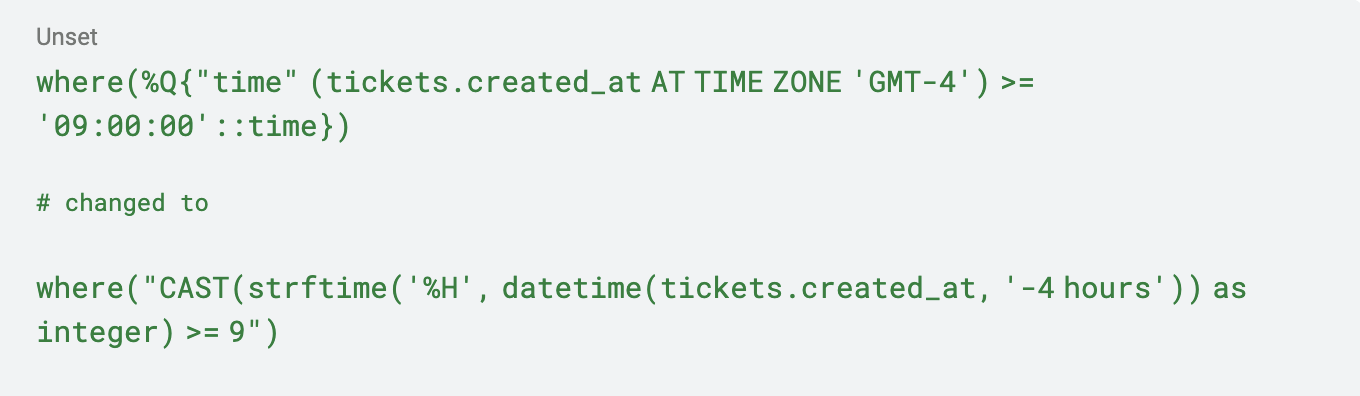
이것은 끔찍한 하드코딩된 날짜 수학(일광 절약 시간제를 고려하지 않음)이며 문제를 해결하는 최선의 방법은 아니지만, 작동했고 이전을 계속할 수 있었습니다. 전체적으로 약 20개의 쿼리를 업데이트해야 했지만, 다행히도 리팩토링을 도와줄 유닛 테스트가 있었습니다!
배포의 복잡성
너무 많은 파드
애플리케이션이 로컬 개발 환경에서 잘 실행되기 시작하자, 스테이징 환경에 배포하기로 했습니다. 여기서 흥미로워졌습니다.
SQLite “연결”은 파일 시스템에서 파일을 여는 것뿐이므로, 데이터베이스 자체는 컨테이너의 파일 시스템에 있어야 합니다. 이는 우리가 지속적인 볼륨을 마운트하더라도 배포의 각 파드는 데이터의 다른 버전을 보게 됩니다. 일반적으로 이는 큰 문제가 될 수 있지만, 이 애플리케이션의 경우 결국 잘 작동했습니다.
저는 데이터가 파드 재시작 시 모두 접근할 수 있도록 데이터가 마운트된 단일 복제본 StatefulSet를 생성했습니다. 제가 최종적으로 얻은 간단한 버전은 다음과 같습니다.

하지만 기다려보세요, 더 있습니다!
CronJobs? 왜 항상 CronJobs여야만 할까요?
이 애플리케이션은 주기적인 데이터 새로 고침 작업도 필요했습니다. 이전에는 Heroku Scheduler로 구현되었으므로, Kubernetes CronJob로 재구성하려고 했지만, 이는 매번 새로운 파드를 생성합니다. 일반적으로 이는 이상적이지만, 각 파드가 자신의 데이터를 가지는 문제가 발생했습니다. 작업은 성공적으로 실행되지만, 파드가 종료되면 데이터가 사라집니다. 이는 작동하지 않으므로 새로운 혁신적인 솔루션을 생각해야 했습니다.
모든 업데이트는 동일한 파드 내에서 발생해야 하므로, 다음 명령으로 시작하는 2개의 별도 사이드카 컨테이너를 만들었습니다:

이 명령은 10분마다 rails 작업을 실행하고 나머지 시간은 대기합니다.
이것은 StatefulSet 파드 내의 모든 컨테이너가 동일한 볼륨 마운트를 사용하기 때문에 작동합니다. 본질적으로 동일한 파일에 접근할 수 있는 추가 프로세스를 생성하여 예상대로 점진적인 업데이트를 수행합니다.
이것이 프로덕션에 배포될 준비가 되었을 때, 데이터베이스 스키마를 시드하고 전체 데이터 로드를 시작할 방법이 필요했습니다. 다행히도 실행할 수 있는 rails 마이그레이션이 있었습니다. 제가 해야 할 일은 StatefulSet의 파드에 exec하여 rails database:migrate 명령을 실행하는 것이었습니다.
이 접근 방식의 단점
이 특정 사용 사례에서는 잘 작동했지만, 이 접근 방식에는 몇 가지 단점이 있습니다.
가장 큰 단점은 StatefulSet을 단일 파드 이상으로 확장할 수 없다는 것입니다. 이 애플리케이션이 공개 트래픽을 수용해야 했다면 끔찍했겠지만, 이는 단순한 내부 비즈니스 프로세스 자동화 도구로 실행만 하면 되므로 완벽하게 작동합니다. 단일 파드만 있으면 Kubernetes 노드 풀 업그레이드 중에 가끔 다운타임이 발생할 수 있습니다.
또 다른 단점은 도구 부족입니다. 데이터베이스에 “연결”하려면 실행 중인 파드에 쉘로 들어가서 필요한 경우 sqlite3 명령을 로컬에서 실행해야 합니다. 이는 꽤 잘 작동하지만, 원격 데이터베이스에 연결하는 것과 비교하면 다소 불편합니다.
다른 라이브러리의 지원 부족도 문제입니다. SQLite는 많은 프로그래밍 언어에서 잘 지원되지만, ORM 라이브러리 측면에서는 종종 지원이 적습니다. 우리에게는 Rails ActiveRecord가 필요한 모든 것을 지원했지만, 지원 수준은 MySQL과 다릅니다.
전반적으로, 의외로 괜찮다!
이 마이그레이션을 통해 우리는 Heroku 비용을 월 약 $90 USD 줄이고, 기존 Kubernetes 클러스터에서 실행되는 단일 파드로 대체할 수 있었습니다. 만약 비슷한 내부 전용 도구가 다섯 개 또는 여섯 개 정도 있다면, 배포를 단순화하는 훌륭한 옵션이 될 수 있습니다.
성능 측면에서 애플리케이션 페이지 로드 시간은 약 150ms 감소했습니다. 속도를 최적화하지는 않았지만, 사용 경험이 훨씬 좋아졌습니다.
현재 몇 달 동안 내부에서 프로덕션으로 실행되고 있으며, 매우 안정적입니다.
앞으로는 https://dqlite.io/와 같은 것을 사용하여 데이터를 Raft 클러스터에 자동으로 복제하는 애플리케이션이 어떻게 보일지 흥미로울 것 같습니다. 하지만 이는 아마도 별도의 기사가 필요할 것입니다.
전체 솔루션 StatefulSet yaml

1. 애플리케이션 재작업은 정확히 범위에 포함되지 않았고, 아이디어가 작동하는지 확인하고 싶었습니다.
2. 해킹 방식으로 알려져 있습니다.



