
We hebben een oude Rails-applicatie gemigreerd van Heroku, PostgreSQL en Heroku Scheduler naar onze Kubernetes-platform met SQLite en wat Bash-magic. Het resultaat is verrassend goed!
Achtergrond
SQLite is een kleine, ingebedde, volledig uitgeruste database die als een enkel binaire bestand op de schijf wordt opgeslagen. Het biedt een snelle, lichte, ACID-conforme database zonder dat er een aparte service of netwerkverbindingen nodig zijn. Hoewel het oorspronkelijk bedoeld was voor ingebedde apparaten, is het in de loop der jaren uitgegroeid tot een populaire alternatieve voor traditionele databasesystemen.
Bij Harvest hadden we een aantal interne tools die we van Heroku naar onze interne Kubernetes-infrastructuur migreerden. Een daarvan gebruikte een Heroku PostgreSQL-database, en ik had moeite om te beslissen hoe ik deze applicatie het beste kon migreren.
Oorspronkelijk dacht ik eraan de applicatie naar MySQL te porteren om aan te sluiten bij onze productie-database-infrastructuur, maar een collega stelde voor om SQLite als alternatief te bekijken in plaats van nog een MySQL-cluster te draaien. Als dit werkte, zou het zowel de applicatiedistributie vereenvoudigen als ons geld besparen door veel minder pods te draaien.
Deze applicatie is een interne tool die onze supportteam helpt hun tickets bij te houden en had op het moment van migratie slechts ongeveer 30MB aan gegevens, dus dit leek een goede kandidaat om mee te experimenteren.
De herschrijving
Rails heeft ingebouwde ondersteuning voor SQLite, dus het was gewoon een kwestie van de SQLite-gem binnenhalen en de databaseconfiguratie instellen. Toch?
Nou, niet helemaal.
Hoewel SQL een standaard is, kunnen verschillende databases ervoor kiezen om verschillende functies op verschillende manieren te implementeren. En de queries van deze specifieke applicatie waren afhankelijk van enkele PostgreSQL-specifieke datum-tijdfunctionaliteiten die niet in SQLite waren geïmplementeerd.
Ik moest de volgende ActiveRecord-query omzetten.
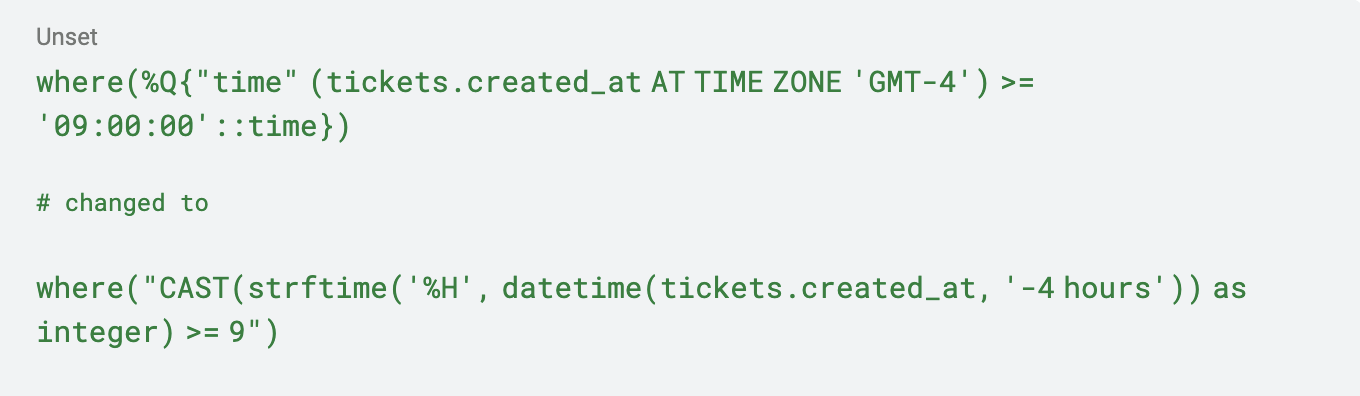
Hoewel dit wat vreselijke hard-coded datummath is (die geen rekening houdt met de zomertijd), en niet de beste manier is om het probleem op te lossen, werkte het en stelde het me in staat om door te gaan met migreren. In totaal moesten ongeveer 20 queries worden bijgewerkt, maar gelukkig waren er unittests om me te helpen refactoren!
Implementatiecomplicaties
Te veel pods
Toen ik de applicatie goed draaide in mijn lokale ontwikkelomgeving, begon ik met de implementatie naar een staging-omgeving. Dit is waar het interessant werd.
Aangezien SQLite "verbindingen" gewoon het openen van een bestand op het bestandssysteem zijn, moet de database zelf op het bestandssysteem van de container staan. Dit betekent dat zelfs als we een persistent volume mounten, elke pod in een implementatie een andere versie van de gegevens ziet. Normaal gesproken zou dit een dealbreaker zijn — maar voor deze applicatie werkte het uiteindelijk goed.
Ik eindigde met het creëren van een single-replica StatefulSet dat de gegevens mountte, zodat de applicatie toegang zou behouden tot al zijn gegevens bij het opnieuw opstarten van de pod. Hier is een vereenvoudigde versie van wat ik uiteindelijk had.

Maar wacht, er is meer!
CronJobs? Waarom moet het altijd CronJobs zijn?
Deze applicatie had ook enkele periodieke gegevensverversingstaken die moesten worden uitgevoerd. Voorheen werden deze geïmplementeerd met een Heroku Scheduler, dus ik probeerde ze opnieuw te creëren met een Kubernetes CronJob, maar die creëren een nieuwe pod bij elke uitvoering. Normaal gesproken zou dit ideaal zijn, maar we stuiten op het probleem dat elke pod zijn eigen gegevens krijgt. De taak zou succesvol draaien, en dan zouden de gegevens verloren gaan wanneer de pod beëindigde. Dat zou niet werken, dus ik moest met een nieuwe, innovatieve oplossing komen.
Alle updates moeten binnen dezelfde pod plaatsvinden, dus ik creëerde 2 aparte sidecar-containers die starten met de volgende opdracht:

Deze opdracht zal de rails-taak elke 10 minuten uitvoeren, terwijl de rest van de tijd wordt geslapen.
Het werkt omdat alle containers in de StatefulSet-pod met dezelfde volume-mounts draaien. Het is in wezen gewoon het starten van een extra proces dat toegang heeft tot dezelfde bestanden en de incrementele update uitvoert zoals verwacht.
Toen dit klaar was voor productie, had ik een manier nodig om het databaseschema te seed en een volledige gegevenslading te starten. Gelukkig was er een rails-migratie die ik kon uitvoeren. Alles wat ik hoefde te doen was in de pod van de StatefulSet te exec-en en de rails database:migrate opdracht uit te voeren.
Nadelen van deze aanpak
Hoewel dit voor ons werkte in deze specifieke use case, zijn er enkele nadelen aan deze aanpak.
De grootste is dat je de StatefulSet niet verder kunt schalen dan een enkele pod. Dit zou verschrikkelijk zijn als deze applicatie verwachtte publiek verkeer te ontvangen, maar dit is een eenvoudige interne tool voor procesautomatisering die gewoon moet draaien, dus het werkt perfect. Slechts één pod betekent dat we soms downtime hebben tijdens upgrades van de Kubernetes-nodepool.
Een ander nadeel is het gebrek aan tooling. Om "verbinding" te maken met de database, moet je in de draaiende pod shellen en sqlite3-opdrachten lokaal uitvoeren voor databaseonderhoud indien nodig. Hoewel dit redelijk goed werkt, is het een beetje ongemakkelijk in vergelijking met het verbinden met een externe database.
Het gebrek aan ondersteuning van andere bibliotheken is ook een probleem. Hoewel SQLite goed wordt ondersteund door veel programmeertalen, krijgt het vaak minder ondersteuning op het gebied van ORM-bibliotheken. Voor ons ondersteunde Rails ActiveRecord alles wat we nodig hadden, maar het niveau van ondersteuning is anders dan bij MySQL.
Al met al, verrassend goed!
Door deze migratie konden we onze Heroku-kosten met ongeveer $90/maand USD verlagen en vervangen door een enkele pod die draait in onze bestaande Kubernetes-clusters. Als je toevallig vijf of zes vergelijkbare interne tools in je omgeving hebt, kan dit een geweldige optie zijn om je implementatie te vereenvoudigen.
Wat betreft de prestaties, de laadtijd van de applicatiepagina daalde met ongeveer 150 ms. Hoewel we niet op snelheid optimaliseerden, maakt het de ervaring van het gebruik ervan veel beter.
Het draait nu al enkele maanden intern in productie en is zeer stabiel.
Als ik vooruit kijk, denk ik dat het interessant zou zijn om te zien hoe deze applicatie eruit zou zien met iets als https://dqlite.io/ om de gegevens automatisch over een raft-cluster te repliceren. Maar dat zal waarschijnlijk zijn eigen artikel vereisen.
Volledige oplossing StatefulSet yaml

1. Het herwerken van de applicatie viel niet precies binnen de scope, en ik wilde nog steeds zien of het idee werkte
2. Ook wel een hacky workaround genoemd.



