
Movemos uma de nossas aplicações internas legadas de Rails do Heroku, PostgreSQL e Heroku Scheduler para nossa plataforma Kubernetes, SQLite e um pouco de mágica em Bash. O resultado final é surpreendentemente não ruim!
Contexto
SQLite é um banco de dados pequeno, embutido e completo que é persistido em disco como um único arquivo binário. Ele oferece um banco de dados rápido, leve e compatível com ACID, sem a necessidade de executar um serviço separado ou usar conexões de rede. Embora seu uso pretendido fosse para dispositivos embutidos, ele cresceu ao longo dos anos e se tornou uma alternativa super popular aos sistemas de banco de dados tradicionais.
No Harvest, tínhamos algumas ferramentas internas que estávamos migrando do Heroku para nossa infraestrutura interna de Kubernetes. Uma delas usava uma instância de banco de dados PostgreSQL do Heroku, e eu estava lutando para decidir a melhor forma de migrar essa aplicação.
Originalmente, pensei em portar a aplicação para MySQL para combinar com nossa infraestrutura de banco de dados de produção, mas um colega sugeriu que deveríamos considerar o SQLite como uma alternativa a mais um cluster MySQL. Se isso funcionasse, simplificaria a implantação da aplicação e nos economizaria dinheiro ao rodar muitos menos pods.
Essa aplicação é uma ferramenta exclusiva para uso interno que ajuda nossa equipe de suporte a acompanhar seus tickets e tinha apenas cerca de 30MB de dados no momento da migração, então parecia um bom candidato para experimentar.
A reescrita
Rails tem suporte embutido para SQLite, então era só uma questão de baixar a gem do SQLite e configurar o banco de dados. Certo?
Bem, não exatamente.
Embora SQL seja um padrão, diferentes bancos de dados podem escolher implementar diferentes recursos de maneiras distintas. E as consultas dessa aplicação específica dependiam de algumas funcionalidades de data e hora específicas do PostgreSQL que não estavam implementadas no SQLite.
Tive que pegar a seguinte consulta do ActiveRecord e convertê-la.
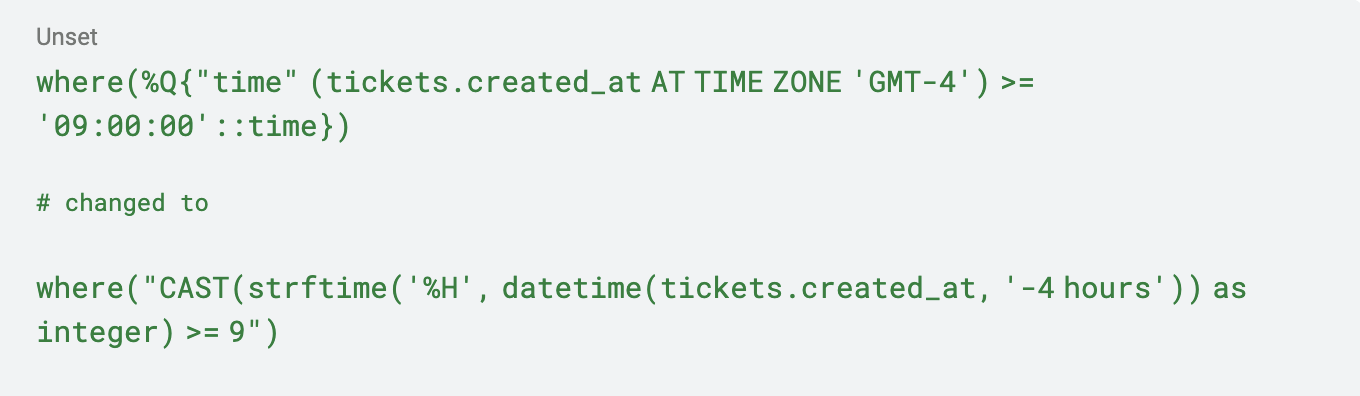
Embora isso seja uma matemática de data codificada de forma terrível (que não leva em conta o horário de verão), e não seja a melhor maneira de resolver o problema, funcionou e me permitiu continuar a migração. No total, cerca de 20 consultas precisaram ser atualizadas, mas felizmente havia testes unitários para me ajudar a refatorar!
Complicações na implantação
Muitos pods
Uma vez que consegui fazer a aplicação funcionar bem no meu ambiente de desenvolvimento local, comecei a implantá-la em um ambiente de staging. É aqui que as coisas ficaram interessantes.
Como as "conexões" do SQLite são apenas a abertura de um arquivo no sistema de arquivos, o banco de dados em si precisa estar no sistema de arquivos do contêiner. Isso significa que mesmo que montemos um volume persistente, cada pod em uma implantação verá uma versão diferente dos dados. Normalmente, isso seria um impeditivo — mas para essa aplicação funcionou bem no final.
Acabei criando um StatefulSet de réplica única que tem os dados montados para que a aplicação mantenha acesso a todos os seus dados após a reinicialização do pod. Aqui está uma versão simplificada do que eu acabei fazendo.

Mas espere, tem mais!
CronJobs? Por que sempre tem que ser CronJobs?
Essa aplicação também tinha algumas tarefas periódicas de atualização de dados que precisavam ser executadas. Anteriormente, essas tarefas eram implementadas com um Heroku Scheduler, então tentei recriá-las com um Kubernetes CronJob, mas esses criam um novo pod a cada execução. Normalmente, isso seria ideal, mas encontramos o problema de que cada pod recebe seus próprios dados. O trabalho seria executado com sucesso, e então os dados seriam perdidos quando o pod terminasse. Isso não funcionaria, então tive que encontrar uma nova solução inovadora.
Qualquer atualização precisa acontecer dentro do mesmo pod, então criei 2 contêineres sidecar separados que iniciam com o seguinte comando:

Esse comando executará a tarefa do Rails a cada 10 minutos, dormindo o resto do tempo.
Funciona porque todos os contêineres no pod do StatefulSet são executados com os mesmos montagens de volume. É essencialmente apenas um processo extra que tem acesso aos mesmos arquivos e realiza a atualização incremental como esperado.
Uma vez que isso estava pronto para ir para produção, eu precisava de uma maneira de semear o esquema do banco de dados e iniciar um carregamento completo de dados. Felizmente, havia uma migração do Rails que eu poderia executar. Tudo o que eu precisava fazer era entrar no pod do StatefulSet e executar o comando rails database:migrate.
Desvantagens dessa abordagem
Embora isso tenha funcionado para nós nesse caso específico, há algumas desvantagens nessa abordagem.
A maior delas é que você não pode escalar o StatefulSet além de um único pod. Isso seria terrível se essa aplicação estivesse esperando receber tráfego público, mas como é uma simples ferramenta de automação de processos internos que só precisa funcionar, funciona perfeitamente. Ter apenas um pod significa que às vezes enfrentamos tempo de inatividade durante as atualizações do pool de nós do Kubernetes.
Outra desvantagem é a falta de ferramentas. Para "conectar-se" ao banco de dados, você precisa acessar o pod em execução e executar comandos sqlite3 localmente para fazer qualquer manutenção no banco de dados, se necessário. Embora isso funcione razoavelmente bem, é um pouco estranho em comparação com a conexão a um banco de dados remoto.
A falta de suporte de outras bibliotecas também é um problema. Embora o SQLite seja bem suportado por muitas linguagens de programação, muitas vezes recebe menos suporte em termos de bibliotecas ORM. Para nós, o Rails ActiveRecord suportou tudo o que precisávamos, mas o nível de suporte é diferente do MySQL.
No geral, surpreendentemente não é ruim!
Com essa migração, conseguimos reduzir nosso custo no Heroku em cerca de $90/mês USD e substituí-lo por um único pod rodando em nossos clusters Kubernetes existentes. Se você tiver cinco ou seis ferramentas internas semelhantes flutuando em seu ambiente, essa pode ser uma ótima opção para simplificar sua implantação.
No que diz respeito ao desempenho, o tempo de carregamento da página da aplicação diminuiu em cerca de 150ms. Embora não estivéssemos otimizando para velocidade, isso melhora bastante a experiência de uso.
Ela está rodando internamente em produção há vários meses e tem sido muito estável.
Olhando para o futuro, acho que seria interessante ver como essa aplicação se comportaria com algo como https://dqlite.io/ para replicar automaticamente os dados em um cluster Raft. Mas isso provavelmente exigirá seu próprio artigo.
Solução completa em YAML do StatefulSet

1. Reestruturar a aplicação não estava exatamente no escopo, e eu ainda queria ver se a ideia funcionava
2. Também conhecido como uma solução improvisada.



